Django ORM


목차
1.QuerySet을 통해 알아보는 ORM의 특징
2.QuerySet 상세
3.실수하기 쉬운 QuerySet의 특성들
4.마치며 QuerySet을 잘사용하는법
참고 자료
이 글은 PyCon 2020 Django QuerySet 발표에 관한 내용을 정리하였습니다.
QuerySet을 통해 알아보는 ORM의 특징
- Lazy Loading 지연로딩 : 정말 필요한 시점에 SQL을 호출한다
지연로딩 예제1)
# User를 선언하는 시점에 users는 다만 쿼리셋에 지나지 않았다.
users: QuerySet = User.objects.all()
if isinstance(users, QuerySet):
print("users는 아직 쿼리셋이기때문에 이 print문이 출력됩니다.")
# list()로 쿼리셋을 불렀을 때 users는 List[Model]이 된다.
user_list: List[User] = list(users) # 리스트로 묶는 시점에 실제 SQL이 호출됩니다.
if isinstance(user_list, QuertSet):
print("user_list는 쿼리셋이 아닙니다. 이 print문은 출력안됨")
# 직렬화 로직
user_list_dict: List[Dict[str, Any]] = [
model_to_dict(user, fields=('id', 'username', 'is_staff', 'first_name', 'last_name', 'email'))
for user in user_list
]
# Dict로 직렬화한 데이터를 json 포맷을 가진 문자열로 풀어준다.
user_list_json_array: str = json.dumps(user_list_dict, indent=1, cls=DjangoJSONEncoder)
# 이 문자열을 httpResponse body(content)에 담아서 반환한다.
return HttpResponse(content=user_list_json_array, content_type="application/json")
위의 쿼리가 실제로 호출되는 시점은 list()로 쿼리셋을 묶는 로직이 수행될때 SQL이 호출된다.
아래는 실제 호출시에 나타나는 로그이다.
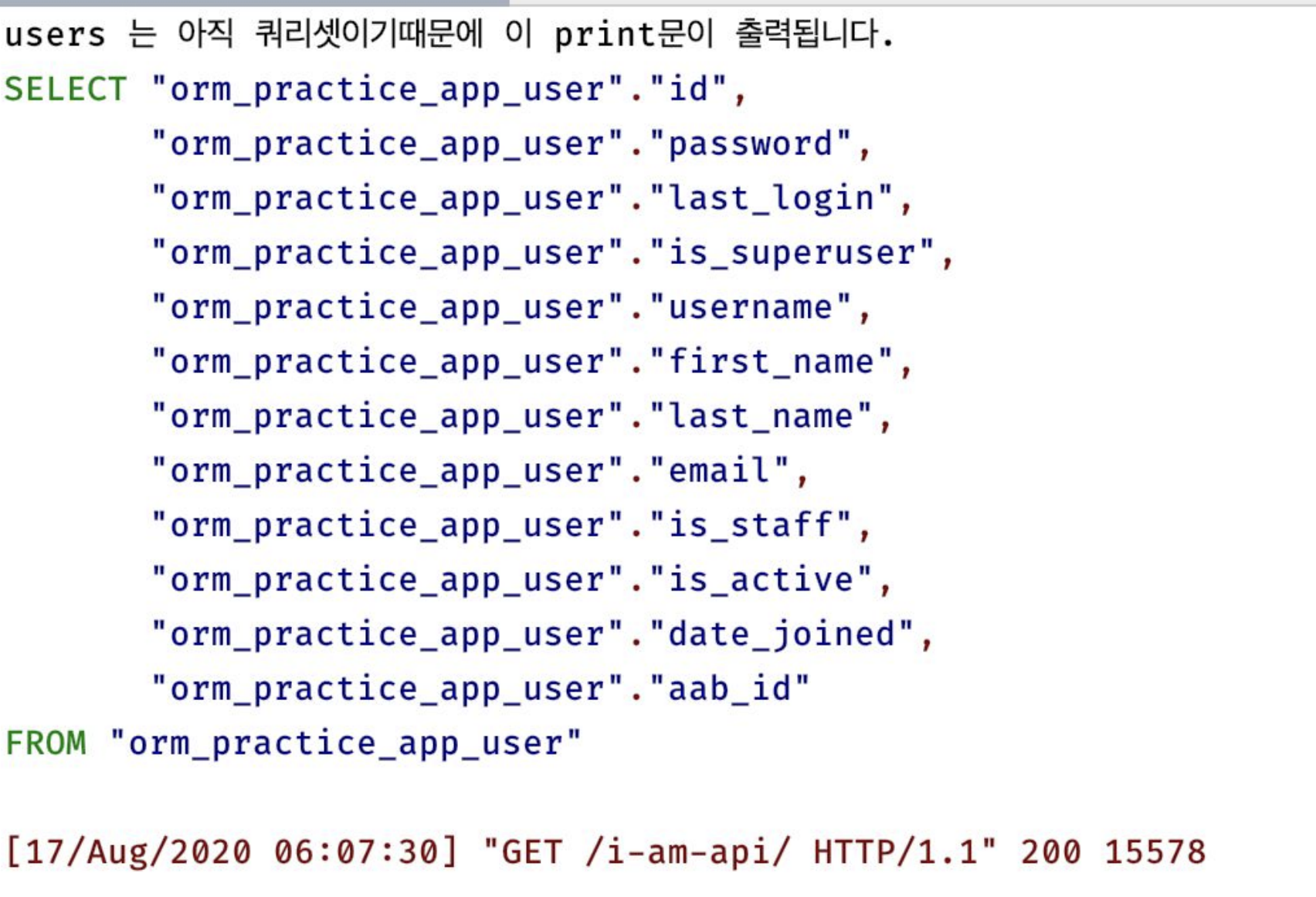
지연로딩 예제2)
- Lazy Loading 지연로딩 : 정말 필요해야만 SQL을 호출한다
def i_am_function_view2(request: WSGIRequest):
print('i_am_function_view2 호출...')
# User를 선언하는 시점에는 SQL이 호출되지 않음
users: QuerySet = User.objects.all()
# 아래 쿼리셋들을 선언만 해놓고 사용하지 않음, 이러면 SQL이 호출되지 않는다.
orders: QuerySet = Order.objects.all()
companies: QuerySet = Company.objects.all()
print('')
user_list: List[User] = list(users)
# 직렬화 로직
user_list_dict: List[Dict[str, Any]] = [
model_to_dict(user, fields=('id', 'username', 'is_staff', 'first_name', 'last_name', 'email'))
for user in user_list
]
user_list_json_array: str = json.dumps(user_list_dict, indent=1, cls=DjangoJSONEncoder)
return HttpResponse(content=user_list_json_array, content_type="application/json")
Order QuerySet과 Company QuerySet을 선언했지만 사용하지 않아서 SQL이 호출되지 않는다.
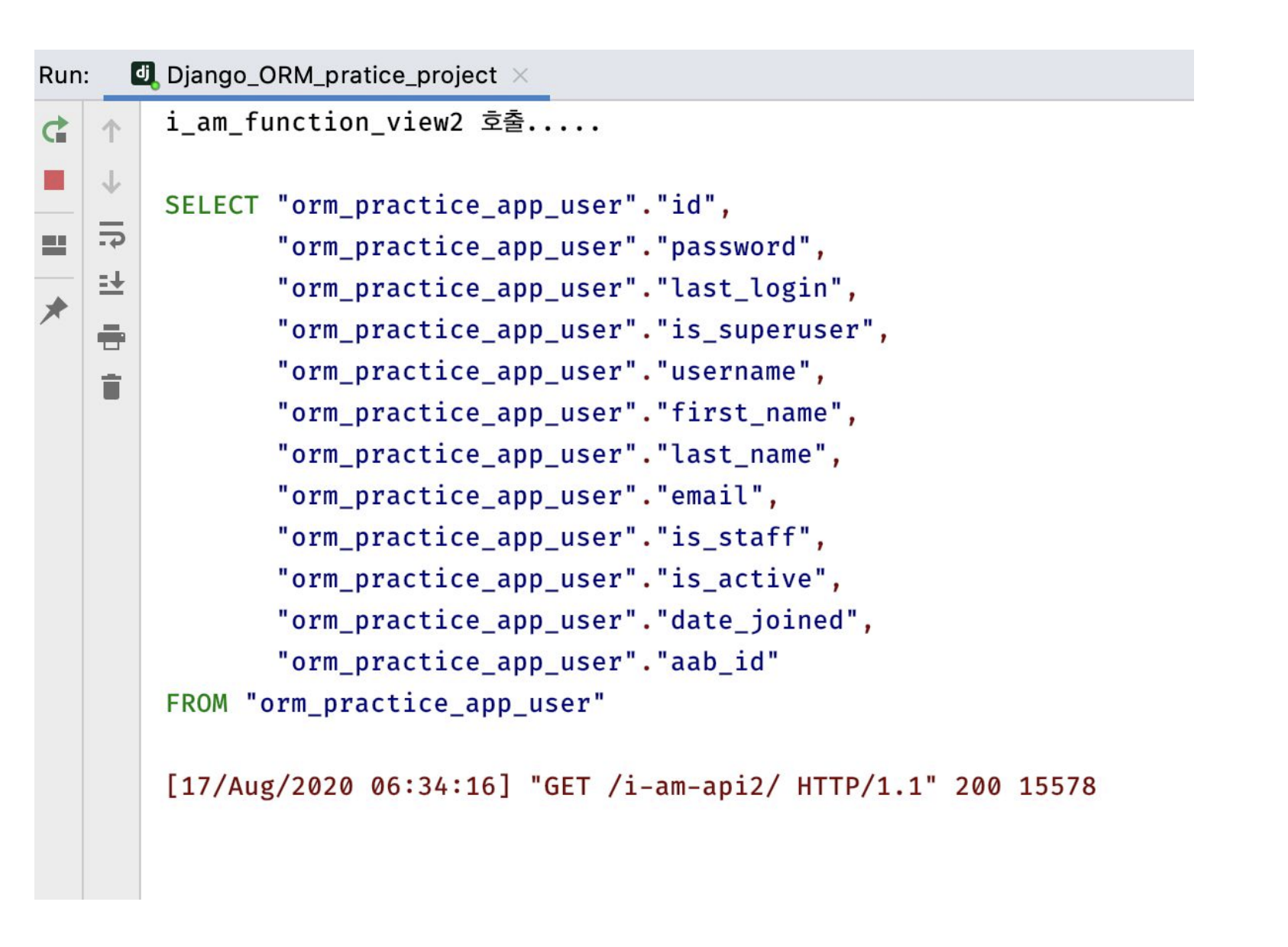
지연로딩 예제3)
- Lazy Loading 지연로딩 : 정말 필요한 만큼만 호출한다.
def i_am_function_view2(request: WSGIRequest):
print('i_am_function_view2 호출...')
# User를 선언하는 시점에는 SQL이 호출되지 않음
users: QuerySet = User.objects.all()
# 0번째 User를 얻어오고싶어서 users쿼리셋은 SQL을 호출
first_user: User = users[0]
# 바로 윗줄에서 user1명밖에 가져오지 않아서 모든 user를 얻으려면 어쩔수 없이 다시 SQL을 호출해야 함
user_list: List[User] = list(users)
# 직렬화 로직
user_list_dict: List[Dict[str, Any]] = [
model_to_dict(user, fields=('id', 'username', 'is_staff', 'first_name', 'last_name', 'email'))
for user in user_list
]
user_list_json_array: str = json.dumps(user_list_dict, indent=1, cls=DjangoJSONEncoder)
return HttpResponse(content=user_list_json_array, content_type="application/json")
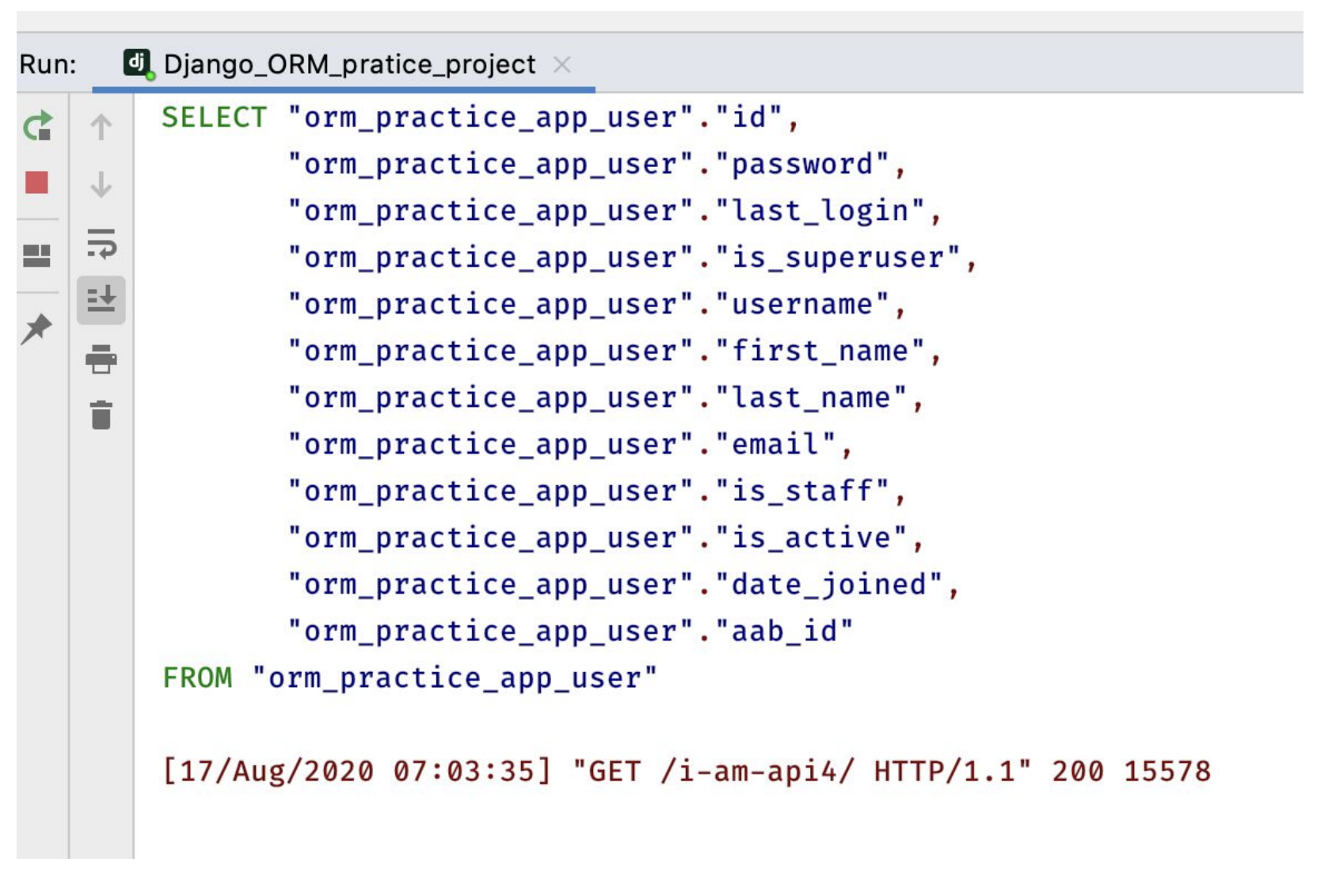
user1명만 얻기위해 LIMIT1 옵션이 걸린 SQL을 호출한다. 그 후에 모든 user목록을 얻기위해 다시 SQL을 호출한다.

지연로딩 해결책
- Caching : QuerySet 캐싱을 재사용하는법 (2-3 해결책)
def i_am_function_view2(request: WSGIRequest):
print('i_am_function_view2 호출...')
# User를 선언하는 시점에는 SQL이 호출되지 않음
users: QuerySet = User.objects.all()
user_list: List[User] = list(users)
# 바로 위에서 users쿼리셋은 모든 user를 가져오는 SQL을 이미 호출함. 따라서, 0번째 user는 users쿼리셋에 캐싱된 값을 재활용함(SQL호출 X)
first_user: User = users[0]
# 직렬화 로직
user_list_dict: List[Dict[str, Any]] = [
model_to_dict(user, fields=('id', 'username', 'is_staff', 'first_name', 'last_name', 'email'))
for user in user_list
]
user_list_json_array: str = json.dumps(user_list_dict, indent=1, cls=DjangoJSONEncoder)
return HttpResponse(content=user_list_json_array, content_type="application/json")
이 예제를 통해 배울점: 쿼리셋을 호출하는 순서가 바뀌는 것만으로도 QuerySet캐싱때문에 발생하는 SQL이 달라질 수 있다.
Eager Loading 즉시로딩 : N+1 Problem
def i_am_function_view2(request: WSGIRequest):
# User를 선언하는 시점에는 SQL이 호출되지 않음
users: QuerySet = User.objects.all()
# 개발자 관점에는 각 user의 모든 userinfo가 필요한 것을 알지만 QuerySet은 그걸 모른다.
for user in users:
# QuerySet의 입장에서 user의 userinfo가 필요한 시점은 여기가 아니다.
# 따라서 userinfo를 알기위해 SQL을 for문이 돌때마다(N번) 호출한다.
user.userinfo
user_list: List[User] = list(users)
# 직렬화 로직
user_list_dict: List[Dict[str, Any]] = [
model_to_dict(user, fields=('id', 'username', 'is_staff', 'first_name', 'last_name', 'email'))
for user in user_list
]
user_list_json_array: str = json.dumps(user_list_dict, indent=1, cls=DjangoJSONEncoder)
return HttpResponse(content=user_list_json_array, content_type="application/json")
이 경우, user.userinfo를 조회할때마다 sql이 계속 호출되는 문제가 발생한다.
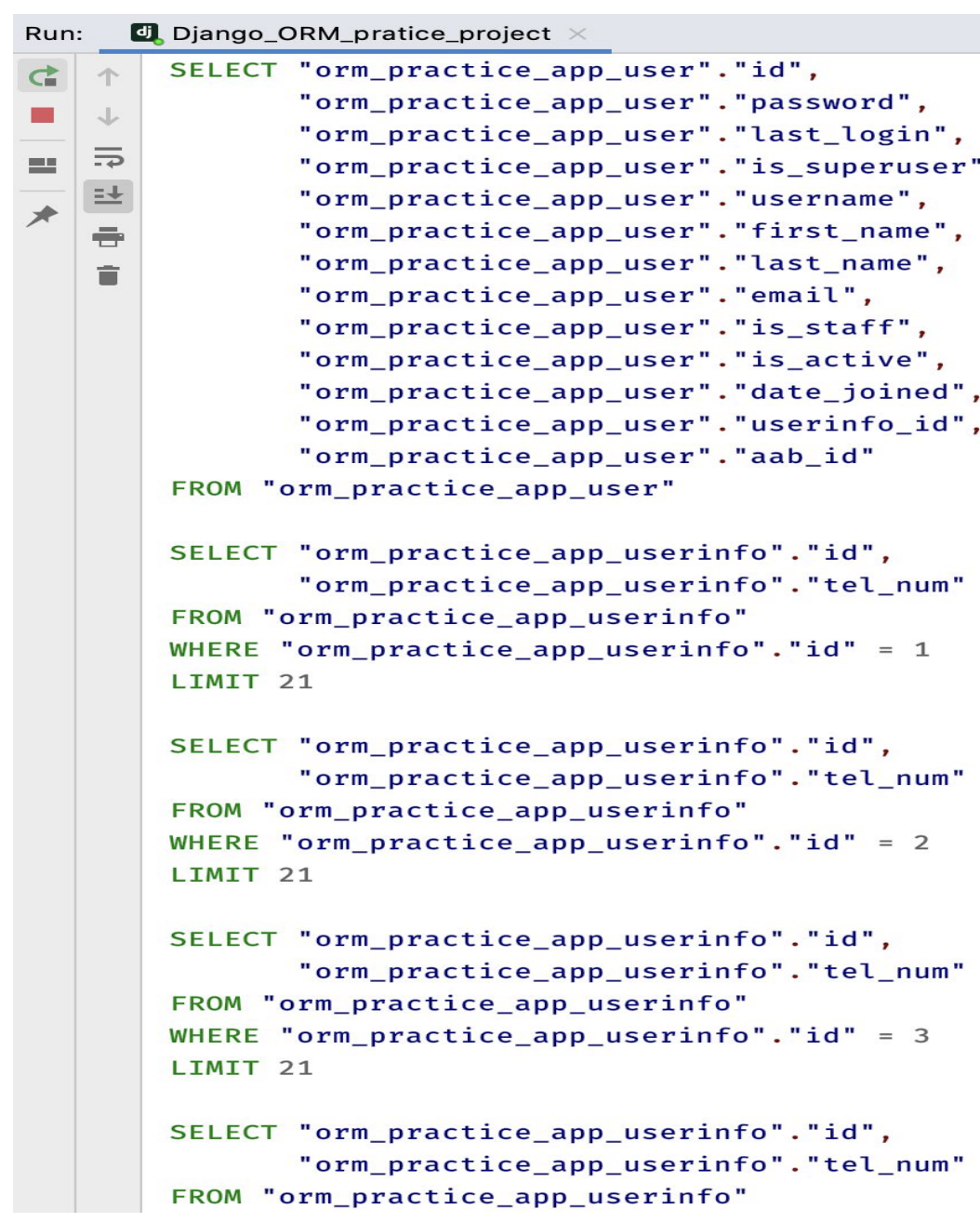
N+1 Problem을 해결하기위해(==즉시로딩을 하기위해) Django는 select_related()와 prefetch_related() 라는 메서드를 제공한다. 이 내용은 아래에서 좀 더 자세히 다룬다.
QuerySet 상세
QuerySet의 구성요소
– 실제 django.db.models.query.py에 있는 QuerySet의 구성요소 –
class QuerySet:
"""Represent a lazy database lookup for a set of objects."""
def __init__(self, model=None, query=None, using=None, hints=None):
self.model = model
self._db = using
self._hints = hints or {}
self._query = query or sql.Query(self.model)
self._result_cache = None
self._sticky_filter = False
self._for_write = False
self._prefetch_related_lookups = ()
self._prefetch_done = False
self._known_related_objects = {} # {rel_field: {pk: rel_obj}}
self._iterable_class = ModelIterable
self._fields = None
self._defer_next_filter = False
self._deferred_filter = None
@property
def query(self):
if self._deferred_filter:
negate, args, kwargs = self._deferred_filter
self._filter_or_exclude_inplace(negate, args, kwargs)
self._deferred_filter = None
return self._query
QuerySet이 어떻게 동작하는지 알기위해서는 아래 구성요소만 알아도된다.
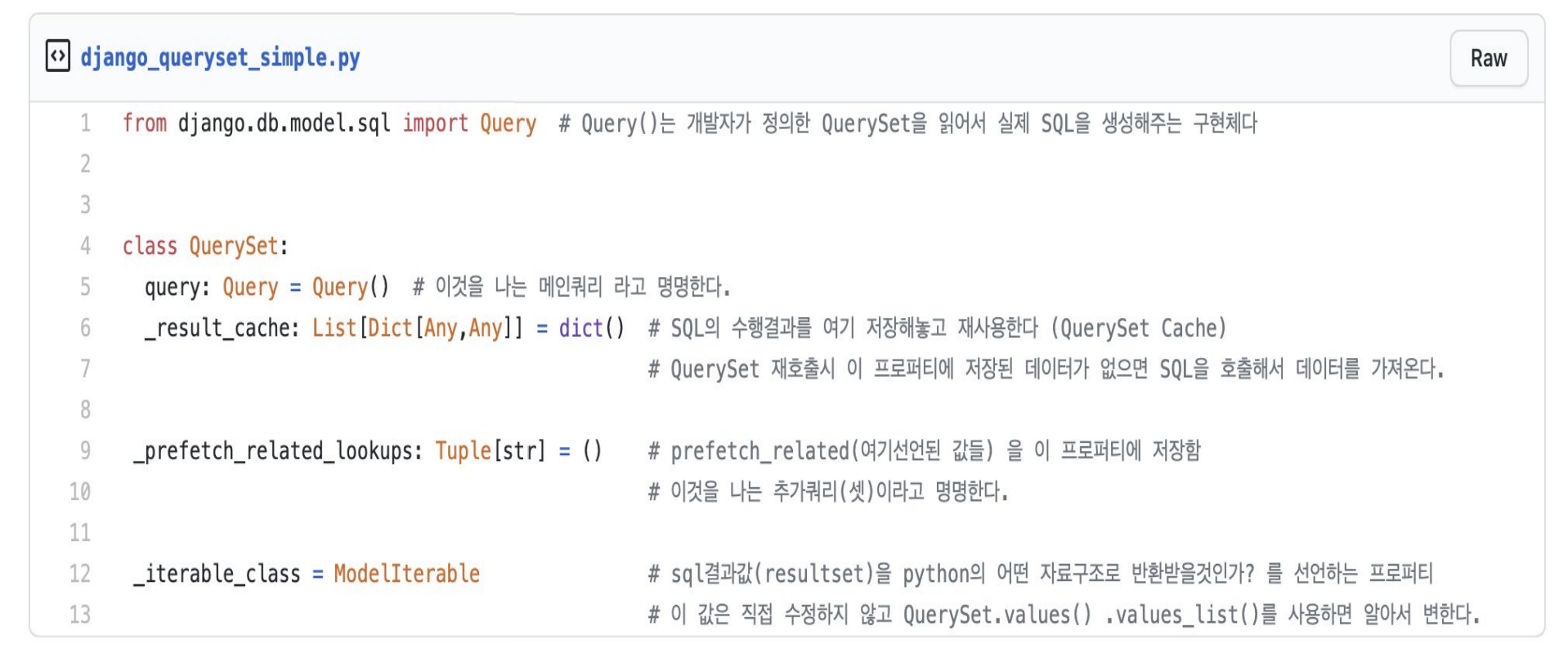
🌟🌟🌟QuerySet은 1개의 쿼리와 0~N개의 추가쿼리(셋)로 구성되어있다. 🌟🌟🌟
select_related()와 prefetch_related()
- prefetch_related()는 추가 쿼리셋이다.

company_queryset: QuerySet = (Company.objects
.filter(name='company_name1')
.prefetch_related('product_set')
)
위의 QuerySet이은 아래와 같이 실행된다. 이를 위해선 2가지 방법이 존재한다.
SELECT *
FROM "orm_pratice_app_company"
WHERE "orm_pratice_app_company"."name" = "company_name1";
SELECT *
FROM "orm_pratice_app_product"
WHERE "orm_pratice_app_product"."product_owned_company_id" IN (1,21);
- 해결책1
company_queryset: QuerySet = (Company.objects
.prefetch_related('product_set')
.filter(name='company_name1', product_name_isnull=False)
)
- 해결책2
company_queryset: QuerySet = (Company.objects
.filter(name='company_name1')
.prefetch_related(
'product_set', Prefetch(queryset=Product.objects.filter(product__name__isnull=False))
)
)
실수하기 쉬운 QuerySet의 특성들
개인적으로 추천하는 QuerySet 작성 순서
queryset = (
Model.objects.
.annotate(
커스텀프로퍼티1선언 = F("DB컬럼명") # sql AS 에 해당
커스텀프로퍼티2선언 = CASE(
When(조건절_모델필드아무거나__isnull=False, # filter질의는 아무거나 다 가능 __gte, __in 등등...
then=Count('특정모델필드')), # 해당 값 기준으로 Count() 함수를 질의함
default=Value(0, output_field=IntegerField(
help_text='해당 애트리뷰트 결과값을 django에서 무슨타입으로 받을건지 선언하는 param입니다.'),
),
)
)
.select_related("정방향_참조모델1", "정방향_참조모델2") # EagerLoading(JOIN)
.filter(Q(), ~Q()).exclude() # 조건절 where문 반영
.only() 또는 .defer() # 필요시에만 사용
.prefetch_related()
)
이 Queryset순서가 실제 SQL의 순서와 가장 유사하다. 다른 건 몰라도 .filter() 문앞에 prefetch_related()를 두면 4-1과 같은 실수를 하기 쉽기 때문에 prefetch_related()는 filter() 뒤에 두는 것을 추천한다.

마치며 QuerySet을 잘사용하는법
- QuerySet은 1개의 Query 와 0~N개의 QuerySet으로 이루어져있다.
- 수행하고자 하는 SQL을 먼저떠올리지말고 가져오고자하는 데이터 리스트를 먼저 떠올리자
- QuerySet이 제공하는 기초적인 SQL구조를 기억하자 이 구조를 벗어난다면 그건 RawQuerySet으로 풀자
- ORM으로 복잡한 SQL을 구현했다고 ORM을 잘쓰는 것이 아니다. 어떤 로직을 작성하는데 단조로운 SQL작업을 줄여주고 Object와 Relational을 Mapping해준다는 ORM의 장점을 얻을수 없다면 그때는 NativeSQL을 사용하자
- NativeSQL(속칭 날쿼리) 사용을 망설이지말아라 특히 SQL성능이 중요한 경우라면, 가끔씩은 Django ORM으로 원하는 쿼리결과를 얻을 수 없을때도 있다. 그리고 또 가끔씩은 가독성 높은 코드가 성능좋은 코드보다 중요할때도 있다.
참고 자료
QuerySet 공부할때 사용한 개인 프로젝트
좀 더 자세한 자료: [Django에서는 QuerySet이 당신을 만듭니다(1)]
좀 더 자세한 자료: [Django에서는 QuerySet이 당신을 만듭니다(2)]
![[Django REST Framework] Serializers](/assets/images/drf-serializers/main.png)

